
Eine der grössten Herausforderungen beim Design einer neuen Applikation ist wohl das Design des Domain Models, beziehungsweise der Datenbank, welche der Applikation als Fundament dient. Die Entitäten, welche hier definiert werden, kommen oft an vielen Stellen in der Applikation wieder zur Verwendung. Entsprechend gravierend sind zu spät festgestellte Fehler im Datenmodell, und entsprechend schwierig ist es, diese nachträglich noch zu korrigieren.
Deshalb möchte ich an dieser Stelle ein Element für die Modellierung des Domain Models vorstellen, welches sich so im klassischen SQL zwar nicht findet, aber dank Abstraktion dennoch möglich ist: Vererbung.
SQL kennt keine Vererbung - ORMs schon
Wie schon angetönt ist Vererbung etwas, das in den klassischen Ausprägungen von SQL (z.B. MySQL oder Transact-SQL) nicht existiert. Jedes Objekt (zum Beispiel die Daten einer Person) wird im SQL als eine Zeile in einer Tabelle abgelegt. Und für alle anderen Datensätze in derselben Tabelle gilt, dass sie gleichwertige Instanzen derselben Entität (als z.B. genau gleiche generische Personen) sind. Es ist nicht möglich zusätzlich eine Entität "Angestellter" zu definieren und mit SQL auszudrücken, dass auch ein Angestellter eine Person ist - entweder eine Person oder ein Angestellter, aber nicht beides.
Im Zusammenspiel mit den zahlreichen heute verfügbaren Frameworks wird jedoch immer seltener direkt mit SQL aus einer Applikation auf einen Datenspeicher zugegriffen. Sehr weit verbreitet sind ORM - Object Relational Mapper, welche dem SQL-Datenmodell ein Domain Model aus Klassen aus der objektorientierten Programmierung entgegenstellen. Und in der objektorientierten Programmierung ist nun Vererbung eines der typischsten Elemente.
Wenn mit einem ORM gearbeitet wird, existiert das Modell für den Datenspeicher zweifach, redundant: Einmal als Datenbank und einmal als Klassenstruktur. Somit gibt es in der Regel zwei Ansätze, um diese beiden Systeme zu entwerfen: Database-First und Code-First. Ersteres bedeutet, dass zuerst die Datenbank entworfen und erstellt wird, und das ORM anhand davon die Klassen generiert. Bei Code-First hingegen werden zuerst die Klassen definiert und daraus die Datenbank. Vererbung kann nur im Code-First Ansatz angewendet werden.
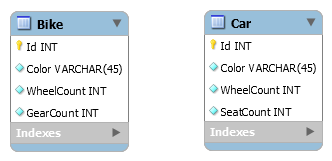
Die Frage, welche nun zu klären ist, was denn passiert, wenn ein ORM mit einem Domain Model konfrontiert wird, welches Vererbung einsetzt. In der Tat ist es so, dass es mehrere Möglichkeiten gibt, eine Vererbungsstruktur nach SQL zu "übersetzen"... Um die Optionen zu illustrieren wird folgendes, einfaches Klassenmodell verwendet:

Die Klassen Bike und Car erben beide von der abstrakten Klasse Vehicle ("Fahrzeug"). Ein Fahrzeug hat als Eigenschaften eine eindeutige ID, eine Farbe und die Anzahl Räder hinterlegt. Fahrräder haben zusätzlich die Eigenschaft, wie viele Gänge vorhanden sind, während Autos über die Information verfügen, wie viele Sitzplätze existieren.
Table-per-Hierarchy (TPH)
Eine erste Möglichkeit besteht darin, die gesamte Vererbungsstruktur auf eine einzige Tabelle zu kollabieren. Dabei werden die Felder, welche alle Unterklassen einführten zur Basisklasse hinzugefügt. Zusätzlich wird eine neue Spalte "Discriminator" generiert, welche dazu dient, die einzelnen Subtypen auseinanderzuhalten.
Als ERD dargestellt, sieht die damit generierte Datenbankstruktur wie folgt aus:

Table-per-Hierarchy hat folgende Vor- und Nachteile:
Vorteile:
- Jedes Objekt wird durch exakt einen Eintrag ("Record") in der Datenbank repräsentiert.
Nachteile:
- Es gibt potenziell sehr viele Felder, welche mit NULL abgefüllt werden müssen da bei jedem Eintrag für ein Auto alle Fahrrad-spezifischen Felder nicht ausgefüllt werden. Anders betrachtet wäre es von Seiten Datenbank her möglich, Autos mit Eigenschaften von Fahrrädern auszustatten und umgekehrt.
- Auf SQL-Ebene ist es nicht möglich, auf den Spalten bestimmte Eigenschaften zu vergeben wie etwa NON-NULLABLE oder UNIQUE
- Sämtliche Referenzen von Unterklassen zu anderen Entitäten werden so umgehängt, dass die Referenz (Foreign Key Constraint) nun auf die Entität Vehicle lautet. Dies kann dazu führen, dass im SQL-Modell ungültige Foreign Key Constraints entstehen, da durch das Zusammenfügen der Entitäten Zirkelbezüge oder mehrfache Kaskade-Pfade entstehen können.
Table-per-Type (TPT)
Beim Ansatz Table-per-Type wird für jede Klasse ("Type") eine eigene Tabelle erstellt. Die entstandenen Tabellen werden mittels 1:1 Referenz miteinander verknüpft. Der Primärschlüssel der Basisklasse dient als Fremdschlüssel und zugleich auch als Primärschlüssel in den erbenden Tabellen.

Vorteile:
- Die Datenstruktur sieht sehr ähnlich wie das Datenmodell mit Klassen aus.
- Alle Felder können wo gewünscht als non-nullable oder unique deklariert werden.
Nachteile:
- Die Objekte sind "verteilt". Eine Instanz von "Bike" wird im SQL als einen Eintrag in der Tabelle "Bike" und als ein Eintrag in der Tabelle "Vehicle" dargestellt.
Table-per-Concrete-class (TPC)
Die dritte Möglichkeit besteht darin, jede konkrete (nicht-abstrakte) Klasse als eigene Klasse zu modellieren. Dabei werden für jede konkrete Unterklasse alle Felder der Superklassen mit den eigenen Feldern zusammengezogen und daraus eine Tabelle gebildet. Die daraus resultierenden Tabellen werden im SQL nicht miteinander verknüpft.
Vorteile
- Alle Felder können wo gewünscht als non-nullable oder unique deklariert werden.
- Alle Objekte werden als ein einzelner Record abgelegt.
Nachteile
- Mehrere Tabellen haben z.T. mehrere identische Felder.
- Es kann im SQL kaum noch allgemein nach z.B. "alle roten Fahrzeuge" gesucht werden, da zwischen den Tabellen keine Relationen mehr bestehen.
- Es ist nicht möglich, dass abstrakte Klassen andere Entitäten referenzieren.
Wahl des Ansatzes
Welcher Ansatz gewählt werden sollte hängt einerseits davon ab, ob die Diskrepanzen der einzelnen Ansätze die gewünschte Modellierung verunmöglichen (etwa wenn eine abstrakte Klasse eine andere Klasse referenzieren soll ist TPC nicht möglich), andererseits aber auch schlicht und einfach, ob das gewählte ORM den Ansatz unterstützt. Während zum Beispiel Entity Framework 6 alle drei Ansätze unterstützt kann Entity Framework Core bisher nur TPH. Hat man damit immer noch mehrere Ansätze zur Auswahl kann man nach dem persönlichen Gusto gehen, bzw. danach urteilen, welche Vor- bzw. Nachteile für einen persönlich überwiegen.